Learning Neo4j with Mikan Oranges
Using Japanese citrus varieties to learn graph modeling with parent-child relationships, family trees, and path queries.
Graph modeling becomes easier when we can see relationships in familiar data.
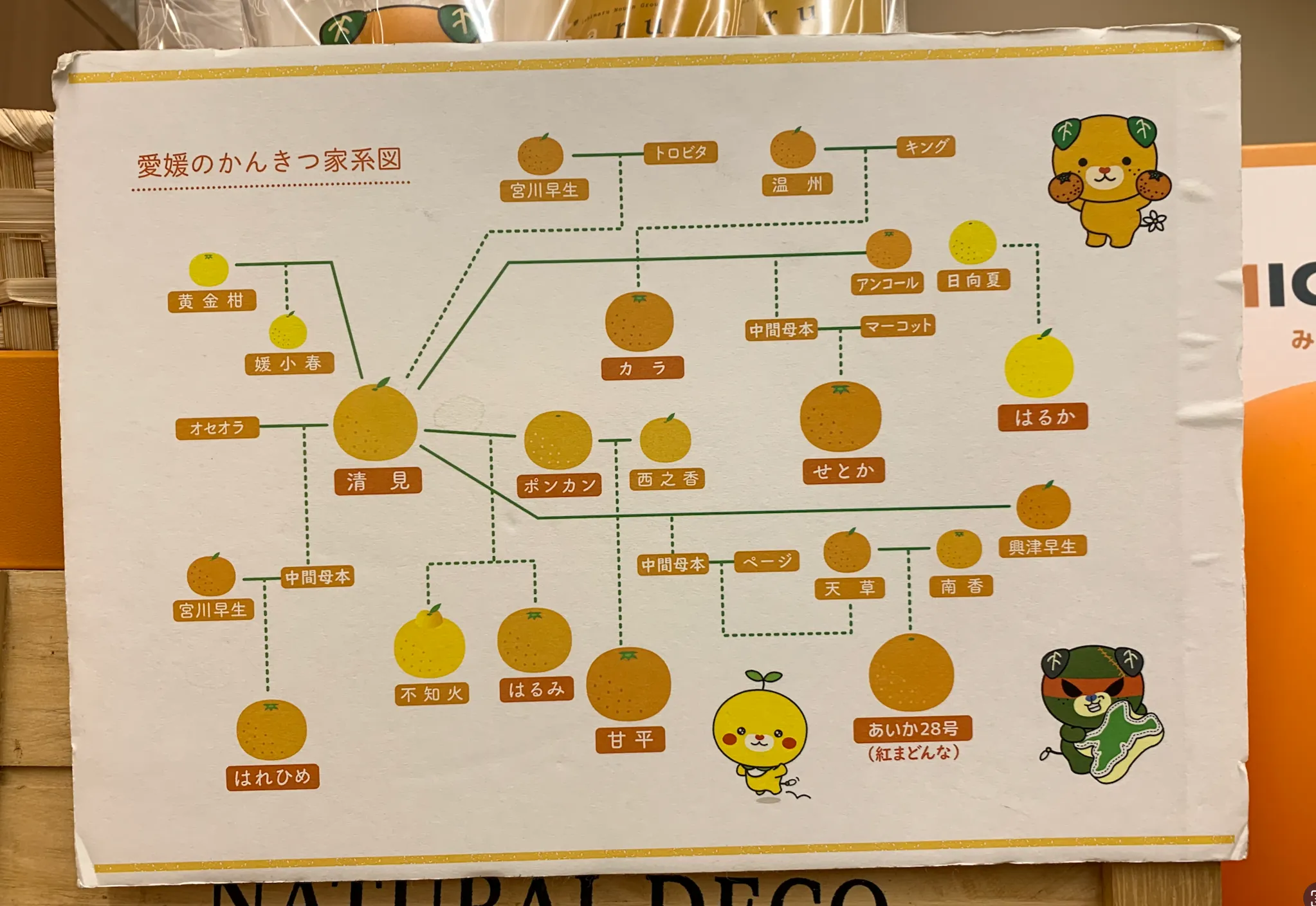
This article uses mikan and other Japanese citrus varieties as a small graph modeling example. The source idea comes from a citrus family tree displayed at Orange BAR in Matsuyama Airport.
A citrus family tree is a good graph example. Each variety can have parent varieties. Some varieties become parents of other varieties. Some paths are short, and some paths continue through multiple generations.
The goal is not only to learn Cypher commands.
The goal is to see how lineage, ancestry, and derivation can be represented as a graph.
日本語補足:
この記事では、みかん・柑橘の品種家系図を題材にして、Neo4j の基本とグラフモデリングを学びます。目的はコマンドを試すことだけではなく、品種の親子関係やルーツをグラフとして表現することです。
Why mikan oranges?
Many graph examples use social networks, product recommendations, or IT systems. These are useful, but a family tree is often easier to understand.
A citrus variety can have parent varieties. A variety can become the parent of another variety. A variety can have many descendants. A variety can also have ancestors several generations back.
These relationships are naturally graph-shaped.
The same pattern appears in many other domains:
- product genealogy
- data lineage
- document versions
- component dependencies
- biological taxonomy
- system inheritance
- knowledge provenance
A citrus family tree is a small and friendly way to learn these ideas.
Starting from a citrus family tree
The original workshop was based on an Ehime citrus family tree displayed at Orange BAR in Matsuyama Airport.
Loading mikan data
The first step is to load citrus variety names from a CSV file.
The full CSV is available as a download. In this article, I show only a few rows so that the main focus stays on graph modeling rather than raw data.
After downloading the CSV, place it under the Neo4j import directory as csv/mikan.csv.
日本語補足:
サンプルCSV全体はダウンロードできます。ダウンロードしたCSVは、Neo4j の import ディレクトリ配下に csv/mikan.csv として配置します。
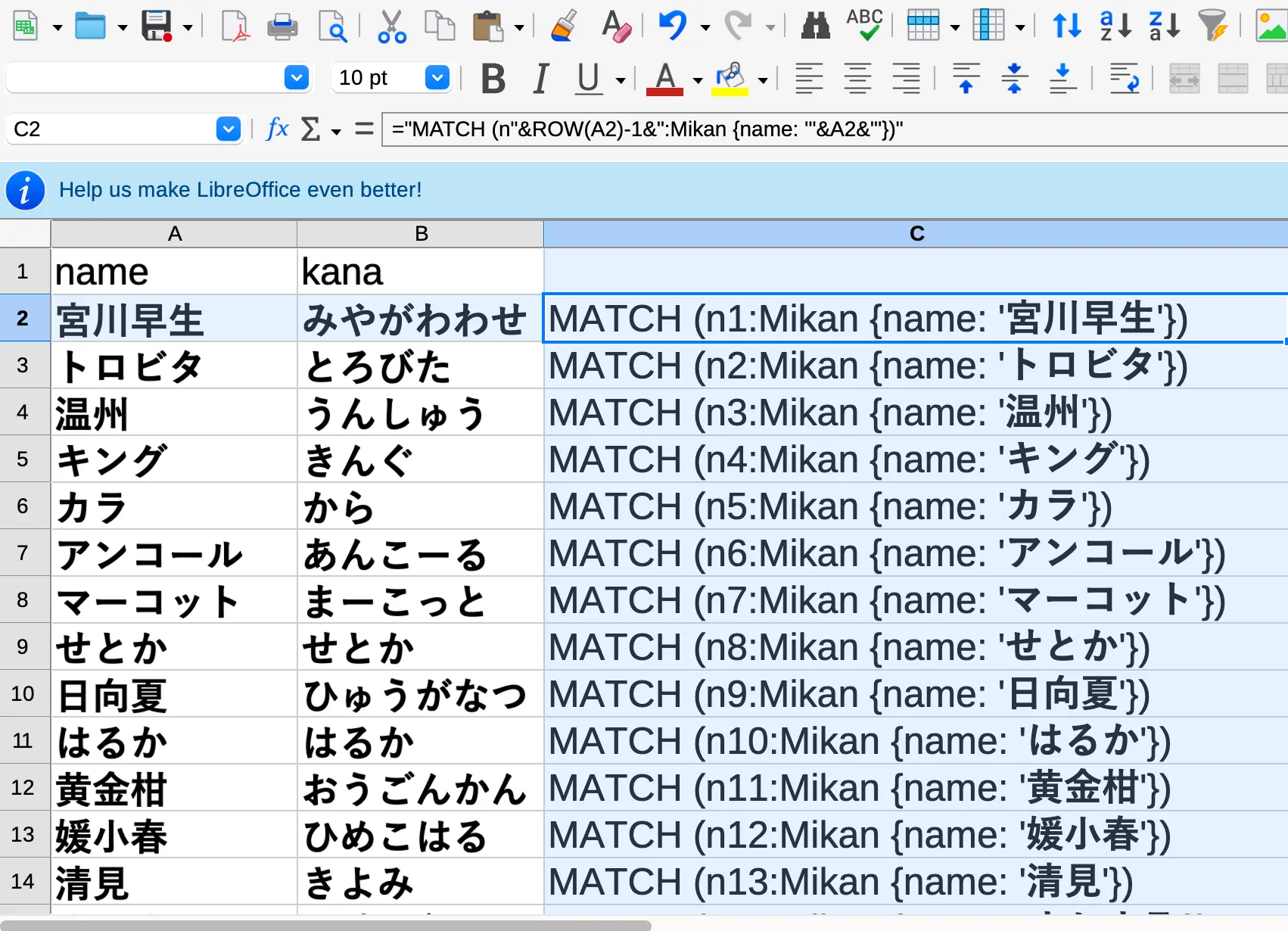
A small part of the CSV looks like this:
"name","kana"
"宮川早生","みやがわわせ"
"トロビタ","とろびた"
"温州","うんしゅう"
"清見","きよみ"
"はれひめ","はれひめ"
"不知火","しらぬい"
"紅まどんな","べにまどんな"Each citrus variety becomes a Mikan node.
LOAD CSV WITH HEADERS FROM 'file:///csv/mikan.csv' AS line
INSERT (n:Mikan {
name: trim(line.name),
kana: trim(line.kana)
});The dataset includes variety names such as:
- 宮川早生
- トロビタ
- 清見
- はれひめ
- ポンカン
- 不知火
- 甘平
- 紅まどんな
- 興津早生
These are Japanese names, so the query examples also use Japanese text. Neo4j can store and search Japanese strings as normal text.
Searching Japanese text
Once the nodes are loaded, we can search by name.
For example, to find varieties whose names include 早生:
MATCH (n:Mikan)
WHERE n.name CONTAINS '早生'
RETURN n;We can also search by kana.
MATCH (n:Mikan)
WHERE n.kana CONTAINS 'わせ'
RETURN n;This is a simple query, but it is useful. It shows that we can start with text data first, then add relationships later.
日本語補足:
まずは名前やかなで検索します。最初から完璧なグラフモデルを作る必要はありません。既存のテキストデータを読み込み、少しずつ関係を追加していきます。
Creating the first parent-child relationship
Let’s start with a small example.
In this simplified model, 宮川早生 and トロビタ are parent varieties of 清見.
MATCH (n1:Mikan {name: '宮川早生'})
MATCH (n2:Mikan {name: 'トロビタ'})
MATCH (n3:Mikan {name: '清見'})
INSERT (n1)-[:PARENT_OF]->(n3)
INSERT (n2)-[:PARENT_OF]->(n3);Now we can see the first parent-child relationship.
MATCH p=()-[r:PARENT_OF]->()
RETURN p
LIMIT 25;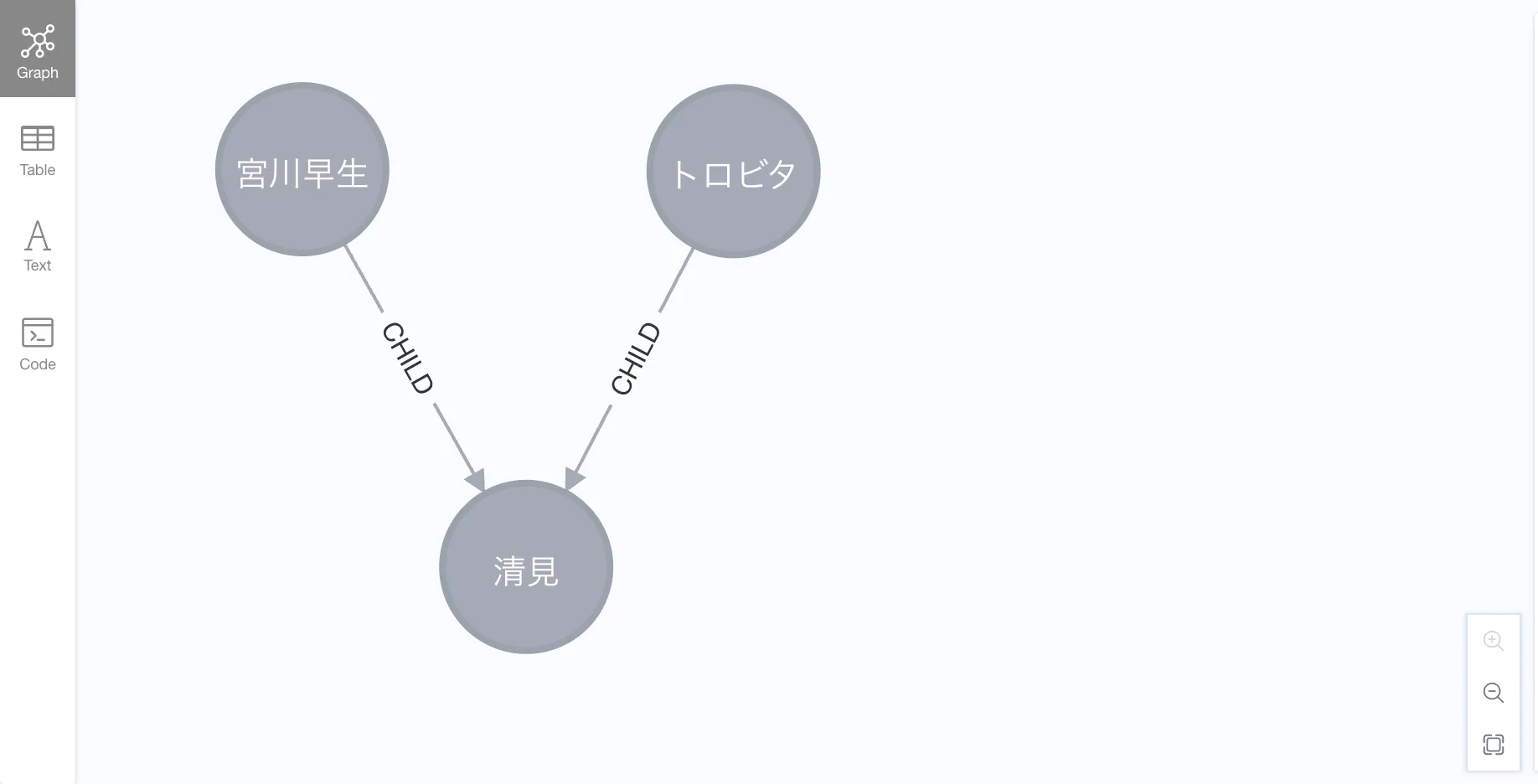
This is the basic pattern of the article.
A parent variety points to a child variety.
(parent)-[:PARENT_OF]->(child)Building the citrus family tree
Next, we add the remaining parent-child relationships.
The original workshop generated many MATCH statements using a spreadsheet. This is a practical approach when the number of varieties is small and the data is prepared manually.
The following example adds the main relationships.
MATCH (n1:Mikan {name: '宮川早生'})
MATCH (n2:Mikan {name: 'トロビタ'})
MATCH (n3:Mikan {name: '温州'})
MATCH (n4:Mikan {name: 'キング'})
MATCH (n5:Mikan {name: 'カラ'})
MATCH (n6:Mikan {name: 'アンコール'})
MATCH (n7:Mikan {name: 'マーコット'})
MATCH (n8:Mikan {name: 'せとか'})
MATCH (n9:Mikan {name: '日向夏'})
MATCH (n10:Mikan {name: 'はるか'})
MATCH (n11:Mikan {name: '黄金柑'})
MATCH (n12:Mikan {name: '媛小春'})
MATCH (n13:Mikan {name: '清見'})
MATCH (n14:Mikan {name: 'オセオラ'})
MATCH (n15:Mikan {name: '中間母本'})
MATCH (n16:Mikan {name: 'はれひめ'})
MATCH (n17:Mikan {name: 'ポンカン'})
MATCH (n18:Mikan {name: '不知火'})
MATCH (n19:Mikan {name: 'はるみ'})
MATCH (n20:Mikan {name: '西之香'})
MATCH (n21:Mikan {name: '甘平'})
MATCH (n22:Mikan {name: 'ページ'})
MATCH (n23:Mikan {name: '天草'})
MATCH (n24:Mikan {name: '南香'})
MATCH (n25:Mikan {name: '紅まどんな'})
MATCH (n26:Mikan {name: '興津早生'})
// 清見
MERGE (n1)-[:PARENT_OF]->(n13)
MERGE (n2)-[:PARENT_OF]->(n13)
// 媛小春
MERGE (n11)-[:PARENT_OF]->(n12)
MERGE (n13)-[:PARENT_OF]->(n12)
// 中間母本
MERGE (n14)-[:PARENT_OF]->(n15)
MERGE (n13)-[:PARENT_OF]->(n15)
// はれひめ
MERGE (n1)-[:PARENT_OF]->(n16)
MERGE (n15)-[:PARENT_OF]->(n16)
// 不知火
MERGE (n13)-[:PARENT_OF]->(n18)
MERGE (n17)-[:PARENT_OF]->(n18)
// はるみ
MERGE (n13)-[:PARENT_OF]->(n19)
MERGE (n17)-[:PARENT_OF]->(n19)
// 甘平
MERGE (n17)-[:PARENT_OF]->(n21)
MERGE (n20)-[:PARENT_OF]->(n21)
// はるか
MERGE (n9)-[:PARENT_OF]->(n10)
// 紅まどんな
MERGE (n23)-[:PARENT_OF]->(n25)
MERGE (n24)-[:PARENT_OF]->(n25)
// カラ
MERGE (n3)-[:PARENT_OF]->(n5)
MERGE (n4)-[:PARENT_OF]->(n5);We can now show all registered nodes and relationships.
MATCH (n)
RETURN n;
Handling intermediate parents
The original family tree includes 中間母本.
This is important from a modeling perspective.
In this workshop data, 中間母本 is better treated as an intermediate breeding line rather than a single shared variety node.
In graph modeling, this is a good reminder:
A label in the source data is not always a unique entity.
So we add separate 中間母本 nodes where needed.
MATCH (n6:Mikan {name: 'アンコール'})
MATCH (n7:Mikan {name: 'マーコット'})
MATCH (n8:Mikan {name: 'せとか'})
MATCH (n13:Mikan {name: '清見'})
MATCH (n22:Mikan {name: 'ページ'})
MATCH (n23:Mikan {name: '天草'})
MATCH (n26:Mikan {name: '興津早生'})
// 中間母本
INSERT (add1:Mikan {name:'中間母本', kana:'ちゅうかんぼほん'})
INSERT (add2:Mikan {name:'中間母本', kana:'ちゅうかんぼほん'})
// 中間母本 for せとか
MERGE (n13)-[:PARENT_OF]->(add1)
MERGE (n6)-[:PARENT_OF]->(add1)
// せとか
MERGE (add1)-[:PARENT_OF]->(n8)
MERGE (n7)-[:PARENT_OF]->(n8)
// 中間母本 for 天草
MERGE (n13)-[:PARENT_OF]->(add2)
MERGE (n26)-[:PARENT_OF]->(add2)
// 天草
MERGE (add2)-[:PARENT_OF]->(n23)
MERGE (n22)-[:PARENT_OF]->(n23);Now the graph represents the family tree more accurately.
MATCH (n)
RETURN n;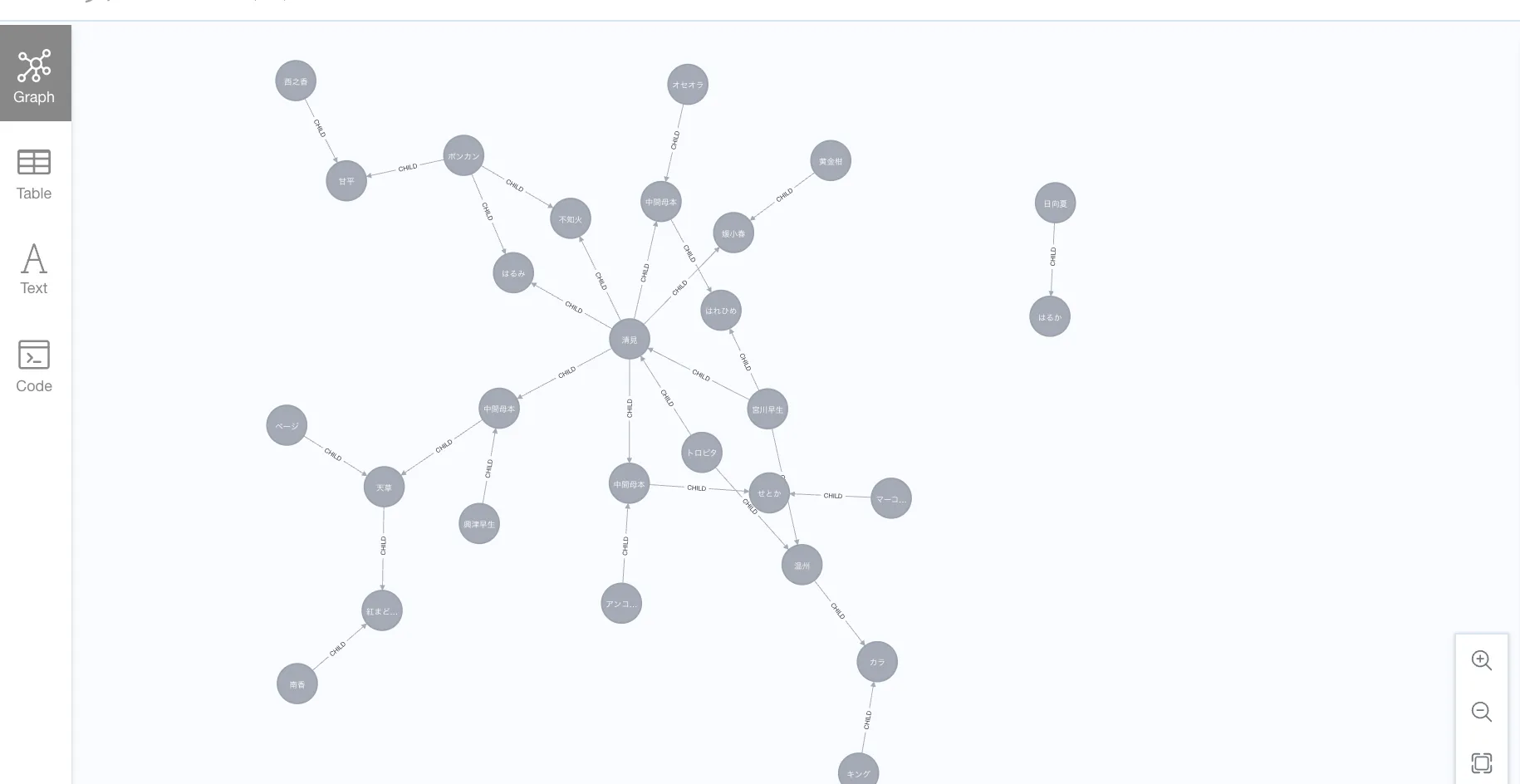
日本語補足:
中間母本 は、特定の一つの品種名というより、中間的な親系統を表している場合があります。このような場合、同じ名前でも同じ実体とは限りません。グラフで表すときは、必要に応じて別ノードとして扱うことが重要です。
Querying a variety
Now we can ask questions about a specific variety.
For example, find 清見.
MATCH (n:Mikan {name: '清見'})
RETURN n;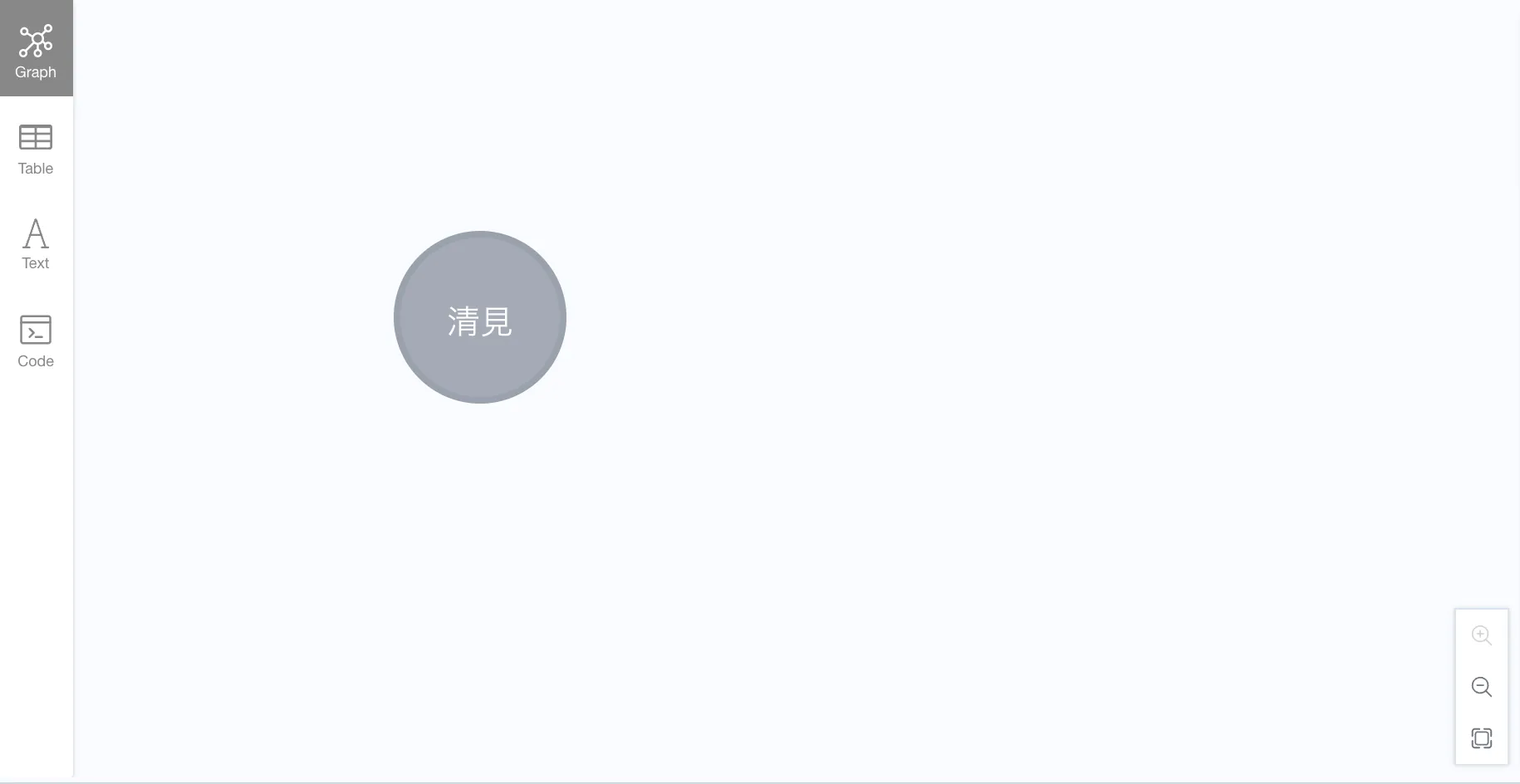
Finding direct children
Which varieties were created from 清見?
MATCH p=(:Mikan {name: '清見'})-->(:Mikan)
RETURN p;We can also specify the relationship type.
MATCH p=(:Mikan {name: '清見'})-[:PARENT_OF]->(:Mikan)
RETURN p;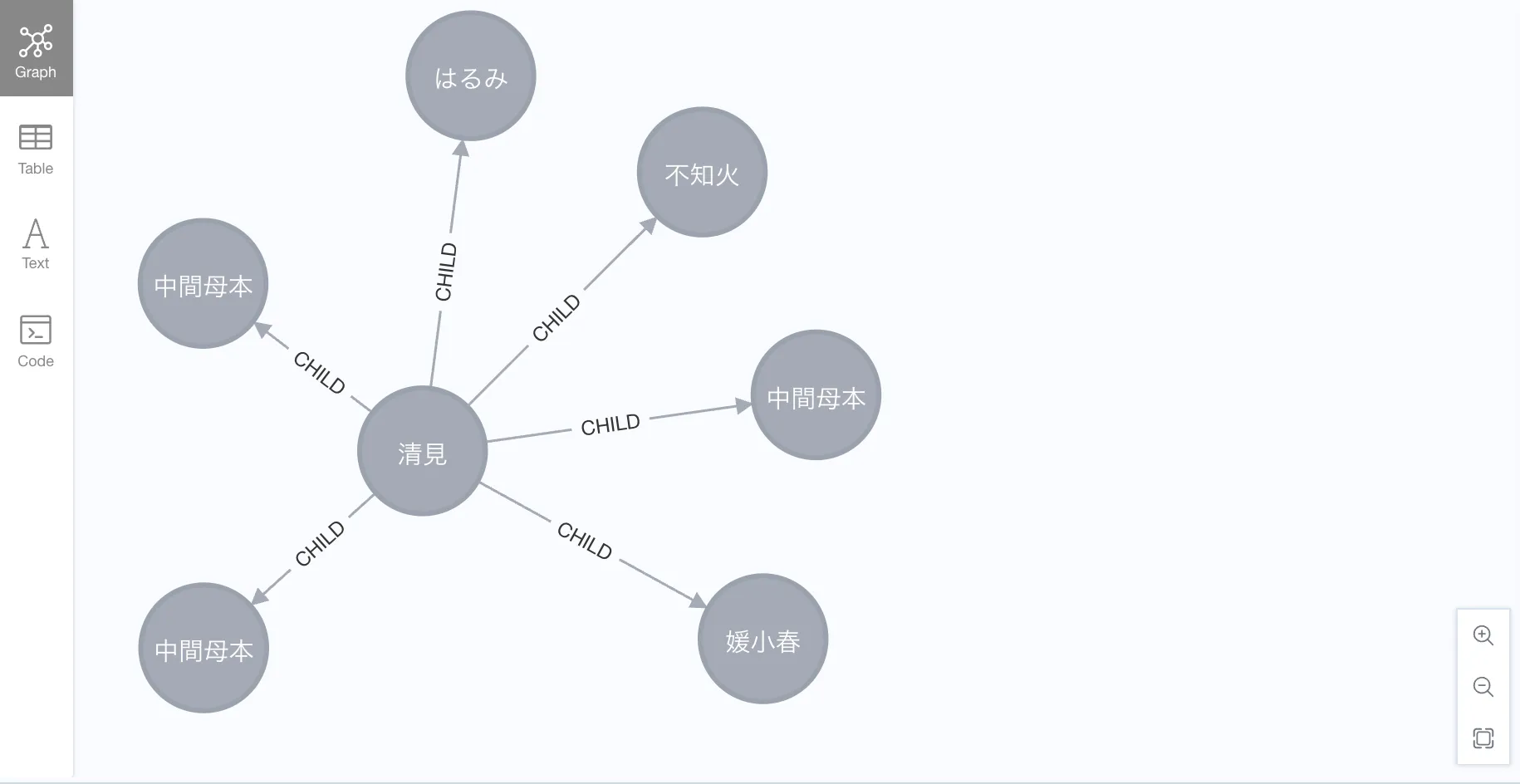
The second query is more explicit. The first query is shorter when the graph has only one relevant relationship type.
Finding descendants
We can also follow the family tree for multiple generations.
Which varieties have 清見 as one of their roots?
MATCH p=(:Mikan {name: '清見'})-->{1,10}(:Mikan)
RETURN p;Or with the relationship type:
MATCH p=(:Mikan {name: '清見'})-[:PARENT_OF]->{1,10}(:Mikan)
RETURN p;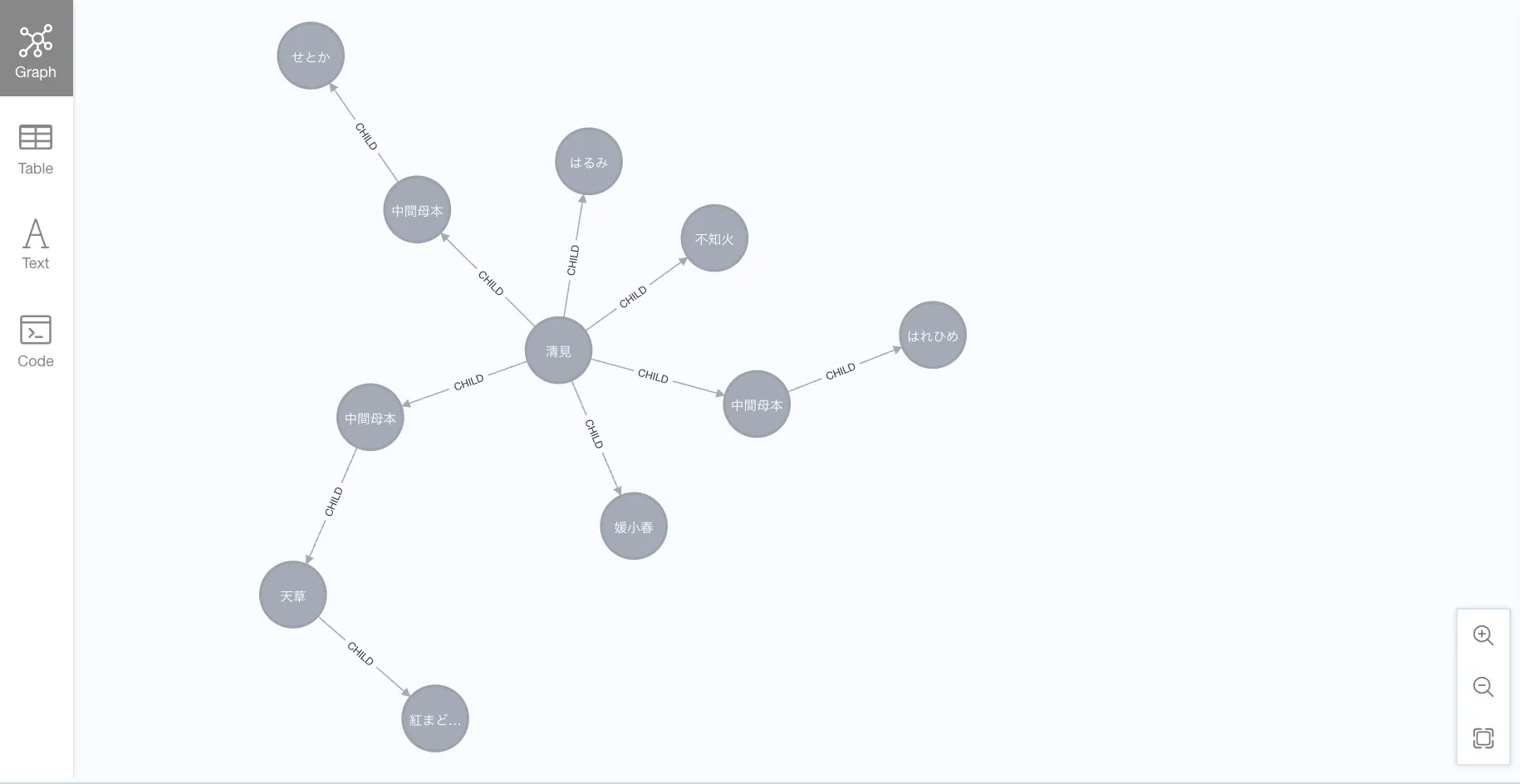
This is where graph databases become useful.
A relational database can store parent-child rows, but graph queries make it natural to follow paths across multiple generations.
Finding parents
We can also query in the opposite direction.
For example, what are the parents of はれひめ?
MATCH p=(:Mikan {name: 'はれひめ'})<--(m:Mikan)
RETURN p;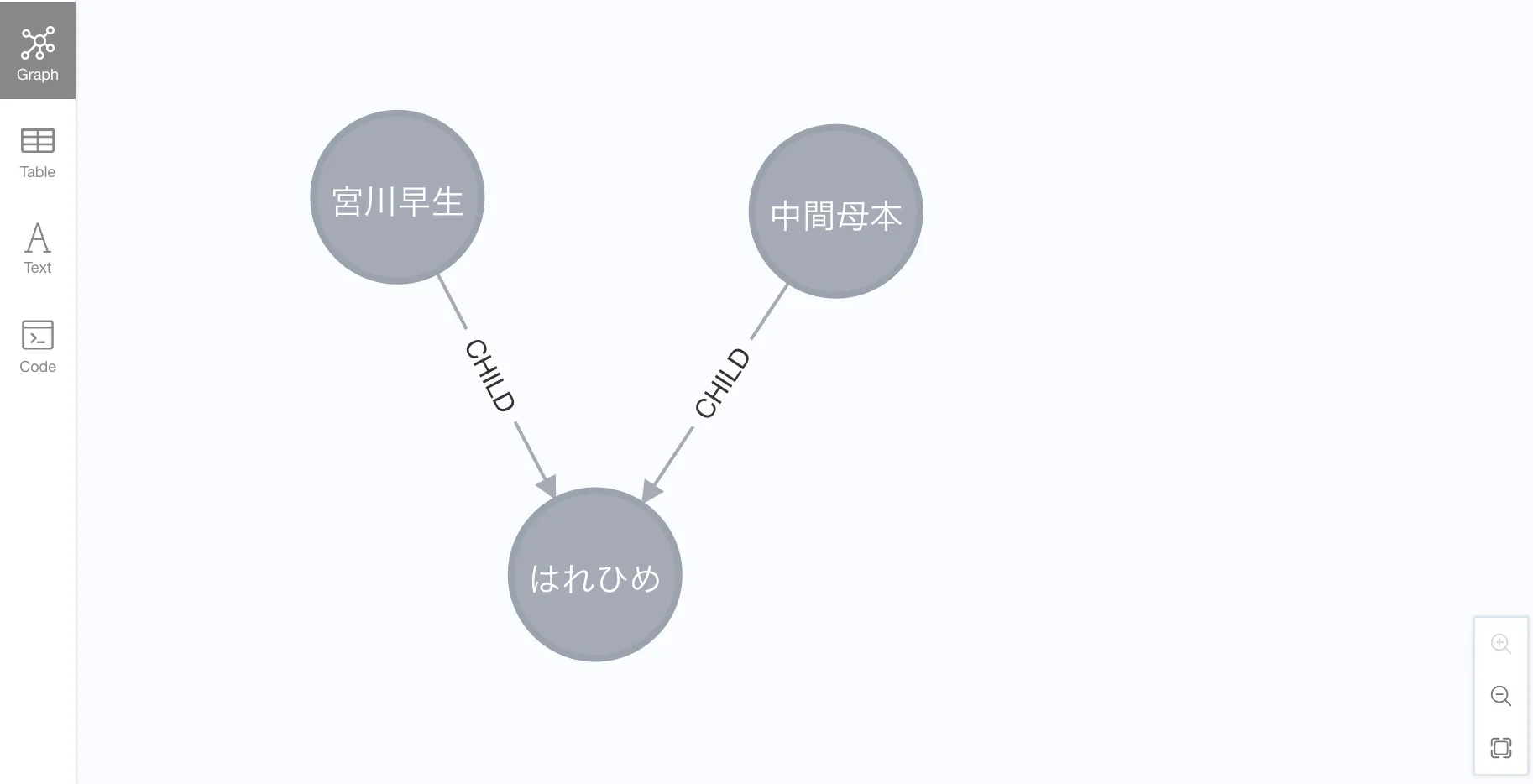
We can also follow ancestors until there are no more parents.
MATCH p=(:Mikan {name: 'はれひめ'})<--{1,10}(m:Mikan)
WHERE NOT (m)<--(:Mikan)
RETURN p;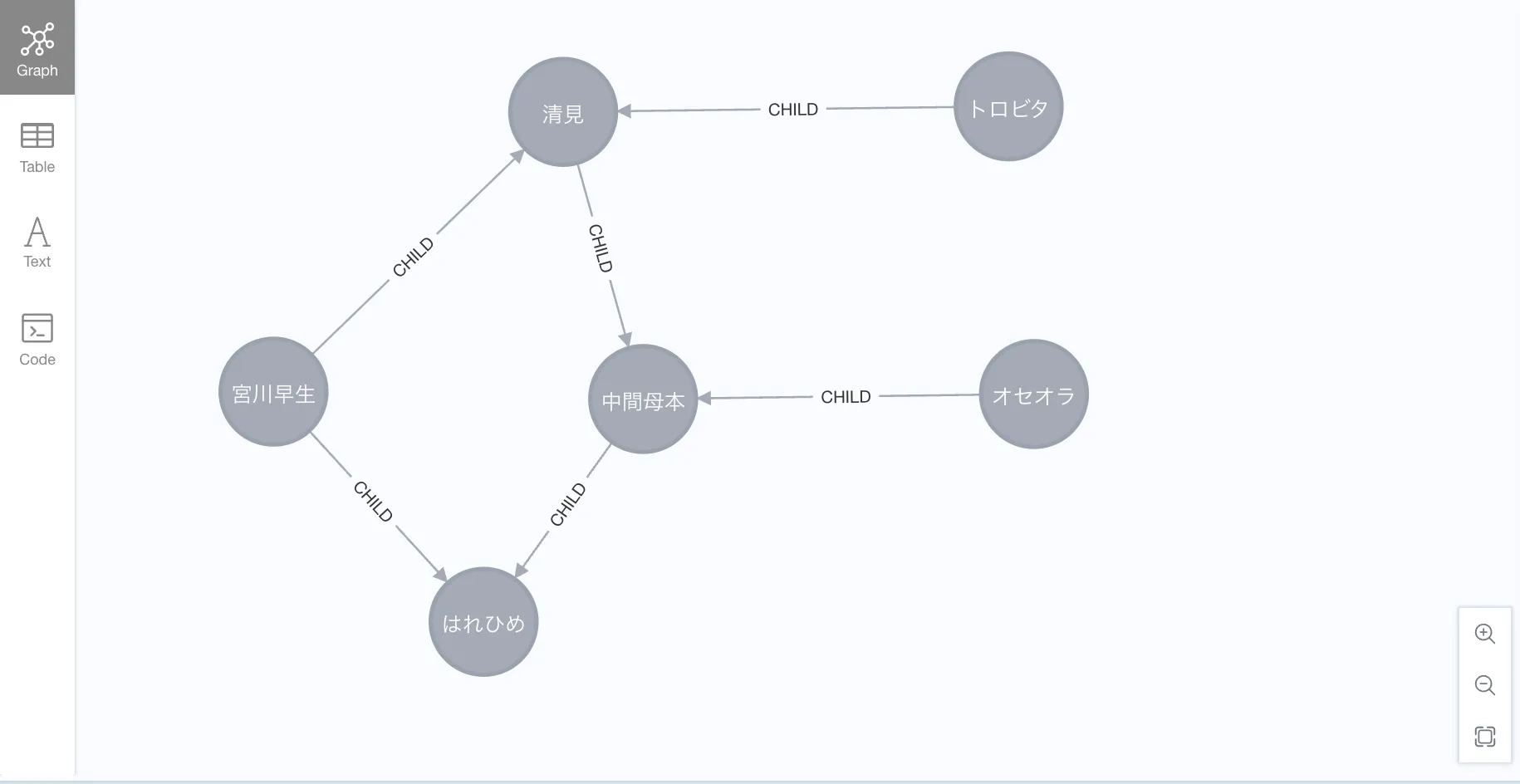
This query is asking:
Which paths go from はれひめ back to the oldest known ancestor varieties?
日本語補足:
はれひめ から親方向へたどることで、祖先にあたる品種を調べることができます。グラフでは、このような「ルーツをたどる」検索が自然に書けます。
Why this matters
This workshop is small, but it shows several important graph modeling ideas.
A variety can be connected to its parent varieties.
A variety can have descendants.
A name in the source data may not always mean one unique entity.
A family tree can be queried as paths.
These patterns are useful far beyond citrus data.
They appear in:
- product genealogy
- data lineage
- system dependencies
- document histories
- software version relationships
- component inheritance
- knowledge graph construction
Graph databases are not only useful for large networks. They are also useful when ordinary data has important relationships.
A citrus family tree is a small example, but it shows the same modeling thinking that appears in real business and technical systems.
A note on relationship names
The original workshop used CHILD as the relationship name.
In this blog version, I use PARENT_OF because the direction is easier to understand:
(parent)-[:PARENT_OF]->(child)The original workshop commands are useful for hands-on learning. This blog version uses a slightly more descriptive name to make the graph model easier to read.
日本語補足:
元のワークショップでは CHILD を使っていますが、この記事では向きが分かりやすいように PARENT_OF にしています。親から子へ向かうリレーションとして読むと、家系図の構造が理解しやすくなります。
Workshop video
The original workshop was prepared for OSC2024 Online/Fall.
You can follow the video and copy the original Cypher commands step by step.
Graph modeling becomes easier when the data is familiar.
For Japanese readers, mikan and citrus varieties are familiar.
For international readers, this is also a good example of how local knowledge, family trees, and lineage can become a small knowledge graph.